Blog
Programming Languages for Pipelined Analytics: Conclusion
Thu 14 January 2016 by Jeff FischerThis is part 4 of my series on pipelined analytics language choices. In this part, we will run performance benchmarks of the file crawler programs and then conclude the series. Here is the outline of the entire series:
- Introduction
- Commentary on the Python and Java implementations
- Commentary on the Go and OCaml implementations
- Performance results and conclusions (this post)
Performance Results
For fun [1], I ran the example file tree walker programs in two scenarios and compared the performance results. In the first case, I walked the local filesystem of a VM on my laptop. The second involved walking an NFS server over the network. The NFS requests should take more time, so one would expect those tests to be more I/O bound.
I ran the Go tests with both the Go 1.4 and the Go 1.5 compilers, just because I had the 1.4 compiler handy at the time. As you will see, there was a non-trivial peformance improvement from 1.4 to 1.5.
| [1] | These benchmarks are very small and should not be considered a complete performance evaluation of the four programming languages. |
Local file system tests
The local tests were run in an Ubuntu 14.04 Virtual Machine with 2 virtual cores that was running on a Macbook Pro with all-flash storage. The entire root filesystem on the VM was walked. There were approximately 74k directories, 604k files, and 1 error (the results would vary slightly for each run). Since the scans complete quickly, I ran the walkers with an iteration parameter of 10. As a result, it made 10 passes over the file tree, for a total of 6 million files. It is likely that the file system metadata has been cached in memory after the first iteration. Thus, this test case emphasizes the user code more than the I/O subsystem.
I timed each walker three times. I then took the mean and standard deviation of the three runs for each walker. The chart below shows the means of the three runs in seconds with error bars for the standard deviation. The full results are on Github here.
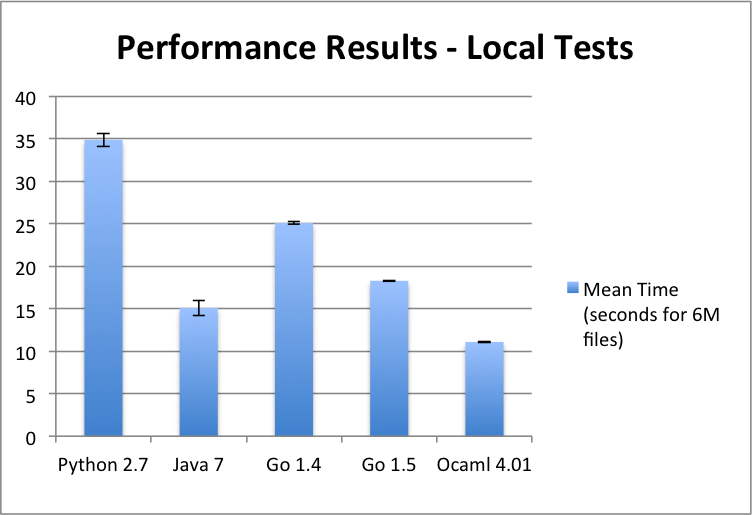
Performance results in seconds - local file walker
The fastest walker (written in OCaml) is about three times faster than the slowest (written in Python). This is to be expected, given what we know about the languages, their compilers, and their runtimes. In the middle, we have Java and Go. Java is faster than Go, which is likely due to greater maturity of the Java compiler and the Hotspot VM. Go 1.5 does show an improvement of 1.4.
Remote file system tests
The NFS tests were run in an Ubuntu 14.04 Virtual Machine with 2 virtual cores that was running in a VMware ESXi environment. The storage, accessed over a network, uses spinning drives in a RAID 7 configuration. The directory tree walked included 10k directories, 5 million files, and no errors.
I ran the walkers with an iteration parameter of 1. I ran each walker 3 times, and then took the mean and standard deviation. The results (in minutes rather than seconds this time) are summarized in the chart below and the full results are here.
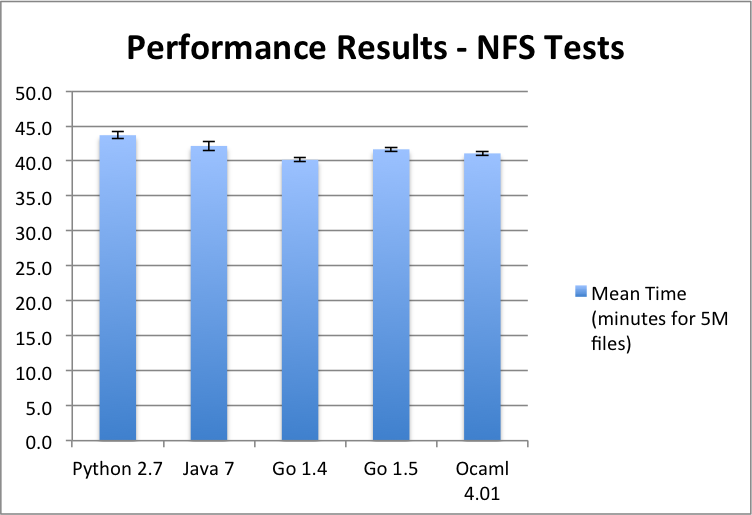
Performance results in seconds - NFS file walker
In this case, the differences in runtimes are much smaller, with only a 9% difference from the fastest (Go 1.4) to the slowest (Python). We do see a dramatic difference between the local and remote runs. The fastest NFS run is over 200 times slower than the fastest local run. These two properties of the results are clearly because the remote network access dominates the runtimes.
Interestingly, the ordering of the languages within the NFS results is different from the local results order. Now, Go 1.4 is the fastest. It would take more analysis to determine exactly why this is the case (e.g. profiling and looking at user/system CPU usage over the run). I suspect that the differences are due to the garbage collection algorithm (maybe Go 1.4's simpler algorithm favors this predictable usage scenario) and/or perhaps the interfaces to the filesystem calls in the C library have less overhead.
Conclusions
In this series, we have looked at the suitability of four programming languages for pipelined analytics. We saw Python, an object-oriented dynamic language, Java, a static-typed object-oriented language, Go, a static-typed procedural language, and OCaml, a static-typed functional language. The languages were qualitatively evaluated on six criteria (performance, expressiveness, error handling/correctness, deployment, and concurrency) and quantitatively evaluated through the use of a file walker example. No single language came out on top in all areas.
Thus, you need to consider the specific situation when selecting one of these languages. Do you need to prototype a solution quickly? Then, maybe Python is the best language. Do you need raw single-thread performance? Then, perhaps OCaml. But, if fine-grained parallelism can be applied to the problem, then Go or Java might be best. There are many criteria to consider, much beyond the scope I can hope to address. Perhaps, this series of articles can help to guide your research. If so, I have accomplished my goal.
Future work
There are several ways in which this analysis could be extended. There are other languages to consider. In particular, I am interested in Scala, an object-functional language which runs on the Java Virtual Machine, and Rust, a lower-level language with influences from ML that provides compile-time checks for memory management and race conditions.
Comparing other example code snippets across the languages would be interesting as well. The file crawler example I used represents the first step in a longer analytics pipeline. We could consider steps that run in the middle (e.g. to perform an aggregation or mapping) as well as endpoint steps (e.g. that save the results to a file).
One could also look at frameworks for pipelined analytics. Many frameworks have appeared in recent years, including Apache Spark Streaming, MillWheel and Cloud Dataflow from Google, Apache Storm, and Datablox (which my company has been involved in developing). What types of problems are each of these best for solving?
I think that is enough for now. If you would like to see more on one of these topics, please follow me on Twitter and let me know what interests you. Thanks!
Programming Languages for Pipelined Analytics: Go and OCaml
This is part 3 of my series on pipelined analytics language choices. In this part, we will look in more detail at Go and OCaml. Here is the outline of the entire series:
- Introduction
- Commentary on the Python and Java implementations
- Commentary on the Go and OCaml implementations (this post …
Programming Languages for Pipelined Analytics
At my startup, we do a lot of "pipelined analytics" — gathering and processing of data across multiple processes over multiple stages. Our current system uses Python, with some C extensions. We've been asked in the past, "Why Python?" The answer is partly developer productivity and partly the nature of the …
read more